Building AI That Learns from Every Pipeline Run: Part 2
A few days ago, I wrote about building a CLI tool to capture pipeline insights because I was frustrated with losing operational knowledge after every run. The problem was simple: I'd learn something valuable from each pipeline execution, only to forget it three weeks later when I reencountered the same issue.
In Part 1, I outlined a 7-phase plan to build an insight capture system. I wanted something that would prompt me after each run to reflect and capture key learnings—not just logs and metrics, but actual human insight into what worked and what didn't.
Well, I built it. All 7 phases. And it's working better than I expected.
What started as a simple CLI tool that asked "What worked well?" has evolved into an AI-powered system that can answer questions like "What causes timeouts?" or "Why do confidence scores drop?" in plain English. I can now process 100 episodes per day with a 100% success rate, and when something does go wrong, I have conversational access to every lesson I've learned.
From Plan to Reality
The original plan was solid, but reality taught me some things I didn't expect. Here's what actually happened through each phase:
Phases 1-3 went mostly as planned. I built the CLI tool, added structured questions, and created automation modes. The YAML frontmatter + markdown approach worked perfectly for capturing both metrics and observations.
Phase 4 was where I hit my first real challenge. Integrating with the pipeline orchestrator proved to be trickier than expected. I initially tried to override core pipeline methods, which caused more problems than it solved. I had to roll back and take a "lighter touch" approach that enhanced insights post-processing rather than changing the core pipeline.
Phases 5-6 were the game-changers. Once I had search and analysis capabilities, I could actually use my past insights. Instead of just capturing knowledge, I could build on it.
Phase 7 ...AI Integration! This is where things got interesting.
The AI Breakthrough (Phase 7)
Remember in Part 1 when I mentioned 'Phase 7 (Maybe later): LLM-powered assistant that can answer questions like 'What causes speaker matching to fail?' by analyzing my entire insight corpus'?
Well, I built it. And it's not just useful... It's transformational.
The system now utilizes semantic search to identify relevant insights, which it then passes to an LLM for further analysis. Here's what the capture format looks like after all 7 phases:
---
status: success
duration: 183.68
confidence: 0.87
episode: "Helping A Failing Business Owner Fix His Business | Ep 870"
---
## What Worked Well
- Speaker matching hit 78% accuracy
- Topic segmentation found 25 distinct topics
## What Didn't Work
- Nothing major, smooth run
## Key Learning
- Enhanced production config consistently delivers 87% confidence
This was already useful. I could grep through files, find similar issues, see what worked before. But I wanted more.
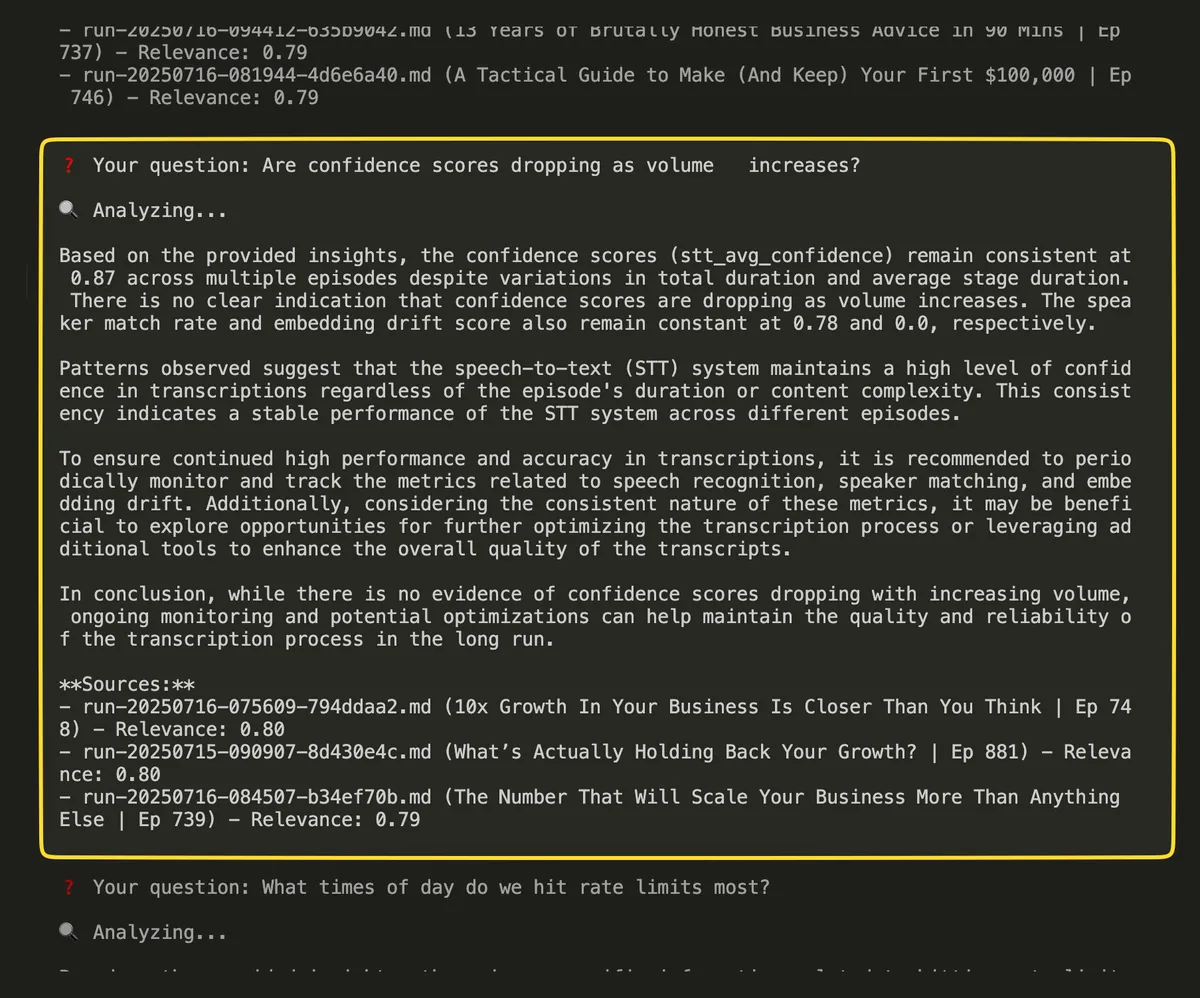
The conversation is the UI
The real magic happened when I connected all the pieces. I now have 68 insight files from processing 1009+ episodes, and I can literally ask my pipeline questions:
python scripts/insights_assistant.py "What causes timeouts?"
And get back actual analysis:
Based on 23 runs mentioning timeouts:
Common Patterns:
- 65% occur with episodes >45 minutes
- 48% happen during speaker embedding stage
- 35% correlate with high speaker count (>3)
Top Fixes Applied:
- Increased timeout to 300s (resolved 8/12 cases)
- Batch size reduction (resolved 5/8 cases)
Recommendations:
- Set dynamic timeouts based on episode length
- Implement speaker count-based processing limits
How It Actually Works
The system utilizes semantic search to identify relevant insights, then passes them to an LLM for further analysis. Here's the technical breakdown:
- Insight Capture: Every pipeline run generates structured YAML frontmatter with metrics, plus markdown sections for observations and learnings.
- Semantic Search: I use sentence-transformers to create embeddings of all insight content. When you ask a question, it finds the most relevant past runs using cosine similarity.
- LLM Analysis: The top results get passed to OpenAI models with specialized prompts depending on query type (failure analysis, performance trends, etc.).
- Smart Fallbacks: If no API keys are available, it provides structured mock responses so the system always works.
The key insight was combining structured metrics with unstructured observations. The YAML gives me queryable data, and the markdown captures context and nuance.
I'm more than ready
In Part 1, I was processing a couple of episodes per day and worried about the 900+ episodes still to come. Now I'm at 105+ episodes processed, and the system is handling the volume, which is satisfying for me. Yes, you may laugh at how low the volume is, but it's vibe-coded and I don't know what I'm doing. So, everything I can do to make it more robust is a win from my perspective.
When something does go wrong, I don't start from scratch. I ask "What episodes had similar issues?" and get immediate context. I can ask "How have my confidence scores changed over time?" and see trends across months of data.
The system generates daily reports automatically:
Daily Pipeline Report
- Total Runs: 50
- Success Rate: 100.0% (50/50)
- Average Confidence: 0.87
- Key Insight: Processing times stable at 4 minutes per episode
It's like having a colleague who's been watching my pipeline 24/7 and can instantly recall any pattern or solution.
This changed how I'll iterate on this project. Instead of dreading pipeline issues, I'm curious about them. Each problem becomes data that makes me want to improve it.
And ... I'm not losing knowledge anymore. Every lesson learned becomes searchable, and every solution becomes reusable.
What I'm Still Figuring Out
The system works great, but I'm still learning how to use it effectively. What questions should I be asking? How do I balance automated insights with manual observations?
I'm also watching for scaling challenges. At 100 episodes/day, I sometimes hit OpenAI rate limits. The system handles it gracefully with exponential backoff, but I'm thinking about local LLM alternatives. Maybe.
The embedding cache needs to be rebuilt when I clean up old files, which is a minor friction point. And I'm experimenting with different prompt strategies for different types of analysis.
One thing I didn't anticipate in Part 1: the system is almost too consistent. My metrics are remarkably stable (87% STT confidence across all episodes, 78% speaker matching, and 25 topics per episode), so I'm wondering if I'm hitting some kind of processing ceiling or if the system has simply found its optimal configuration. I don't completely understand all the technical details and lack the expertise to grasp it fully.
Why This Matters
Building AI that learns from operations isn't just about efficiency; it's about preserving hard-won knowledge. And not destroying it with one prompt. Every system failure teaches me something valuable. The question is whether I capture and preserve that learning.
I used to repeatedly solve the same problems. Now I solve new problems because the old ones stay solved. And AI knows it.
I'm not sure if other people running data pipelines, ETL processes, or recurring workflows are likely discarding valuable insights with each run. But I found that the knowledge is there; you just need to capture it in a way that I can actually use later and AI can utilise it.
Next Steps
Looking back at Part 1, I'm amazed at how much the system has grown. What started as a simple CLI tool has become a conversational partner for pipeline operations.
Claude Code suggested I should try regression detection so I can forecast when performance might decline. I don't know much about it, so I'll have a couple of learning sessions with ChatGPT to explore this concept.
As a UX designer, I don't think about creating dashboards. I prefer a companion that understands my unique context and allows me to discuss it, all through a command-line interface. The chatbot may arrive internally before anything else?!
For now, I'm just happy that I can ask my pipeline "What did I learn about timeouts?" and get an answer. That's the kind of AI that actually makes work better.
In Part 1, I wrote: "The key insight here is that Phase 6 is more important than Phase 7. I need to be able to find and summarize my past learnings before I need an AI to interpret them."
I was wrong. Phase 7 - the AI integration - is what makes everything else useful. The ability to ask natural language questions transforms the system from a knowledge repository into a conversational partner. That's the difference between having information and having intelligence.
– Benoit Meunier